
纽约大学发表在PNAS(IF = 9.4)的最新研究“The time course of person perception from voices in the brain” ,揭示了人物特征的神经表征在大脑中何时、如何被感知和解码。

一、引言
我们在听到一个声音后的大约80毫秒时,就开始形成对说话者的多方面印象,包括身体特征(如性别、年龄、健康状况),还包括性格特征(如吸引力、支配力、可信度)和社会特征(如教育水平、职业素养)。本研究使用脑电和表征相似性分析(RSA)来描述这些来自声音的多维印象是如何随着时间的推移在不同的抽象水平上出现的。研究发现,这些印象并非同时形成,而是逐步出现:关于身体特征(如性别、年龄)的印象较早就形成,大约在120毫秒时就能出现;而关于个性特征和社会特征(如吸引力、教育水平等)的印象则稍晚一些,大约在360毫秒之后才开始形成。
二、研究方法
实验共采集32名被试信息。共完成两个测试阶段(EEG测试和行为评分测试)。如图1:
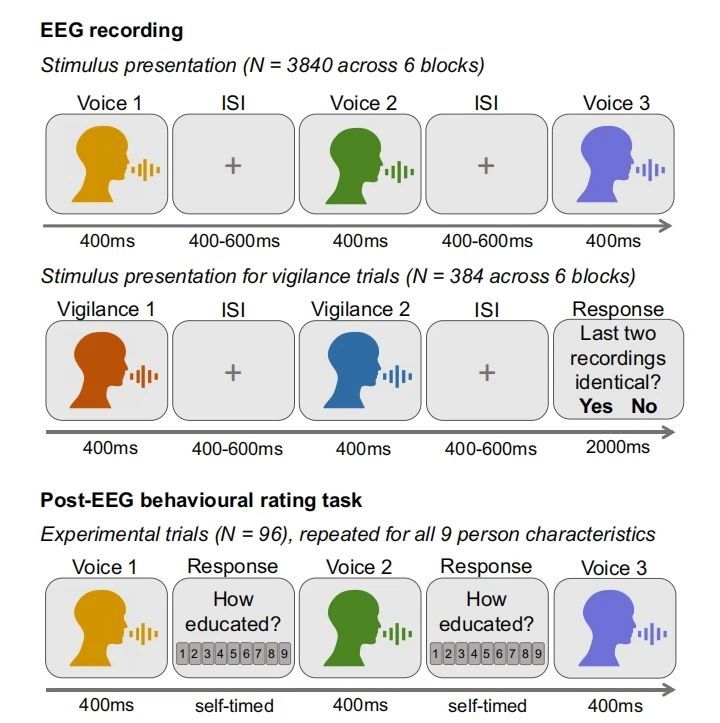
图1:实验流程说明
1、EEG测试阶段:
被试听取96个元音录音样本(96个元音录音样本,每段重复40次,共3840个试次),每段录音的时长为400毫秒。分为6个区块完成,刺激间隔ISI为400~600ms。大约9%的试次中,计算机屏幕会提示完成1-back警觉任务(由26种警觉刺激重复16次,共384个警觉试次),判断两个相邻的录音片段是否相同(元音因素或发声者是否相同)。警觉任务的试次在每个区块内均匀分布,既不会出现在区块的开始,也不会紧接在上一个警觉试次之后。相同的录音对条件下,警觉试次呈现两次相同的语音刺激;不同的录音对条件下,警觉试次先呈现一个随机的测试刺激(由26种测试刺激重复呈现8次,共198个试次),随后再呈现一个警觉刺激。
2、行为评分阶段:
在行为评分阶段,被试再次听取所有EEG记录中用到的录音片段,并给出他们对这些声音的主观评分。评分的内容包括:
身体特征:性别、年龄、健康感、吸引力。
性格特征:主导性、可信赖性、教育程度、专业性。
3、脑电记录:
使用Brain Products的32导主动电极和BrainAmp放大器(国内均由瀚翔脑科学总代理),参考电极贴在鼻尖。
4、声学处理:
使用PRAAT软件从每个语音录音中提取LTAS(长时平均声谱),分析语音录音之间的频率分布差异。此外,提取了多项声学指标:F0均值(基频的平均值)、 前四个共振峰(F1、F2、F3、F4)均值、共振峰散布度(DF);谐波源与非谐波源;谐波噪声比(HNR)等。
三、研究结果:
声音的主观感知特征
考虑到人物特征之间的高度相关性,研究者对每个声音录音的平均评分进行了主成分分析(PCA,oblimin 旋转),对声音录音的评分数据进行降维。相关性分析和PCA进一步确定了不同的人的特征不是彼此独立的,而是高度相互依赖的。
大脑对声音解码表征的时间进程
研究对EEG和行为数据进行了时间分辨率的RSA表征相似性分析(见图2):计算每个录音的平均EEG响应(选取刺激前100毫秒到刺激呈现后700毫秒时间段)。在每个时间点,使用支持向量机(SVM)分类,并通过五折交叉验证来测试该分类模型的准确度。最终生成96x96的神经表征不相似性矩阵(RDM),其中每个元素表示每个被试和每个时间点的解码准确度。
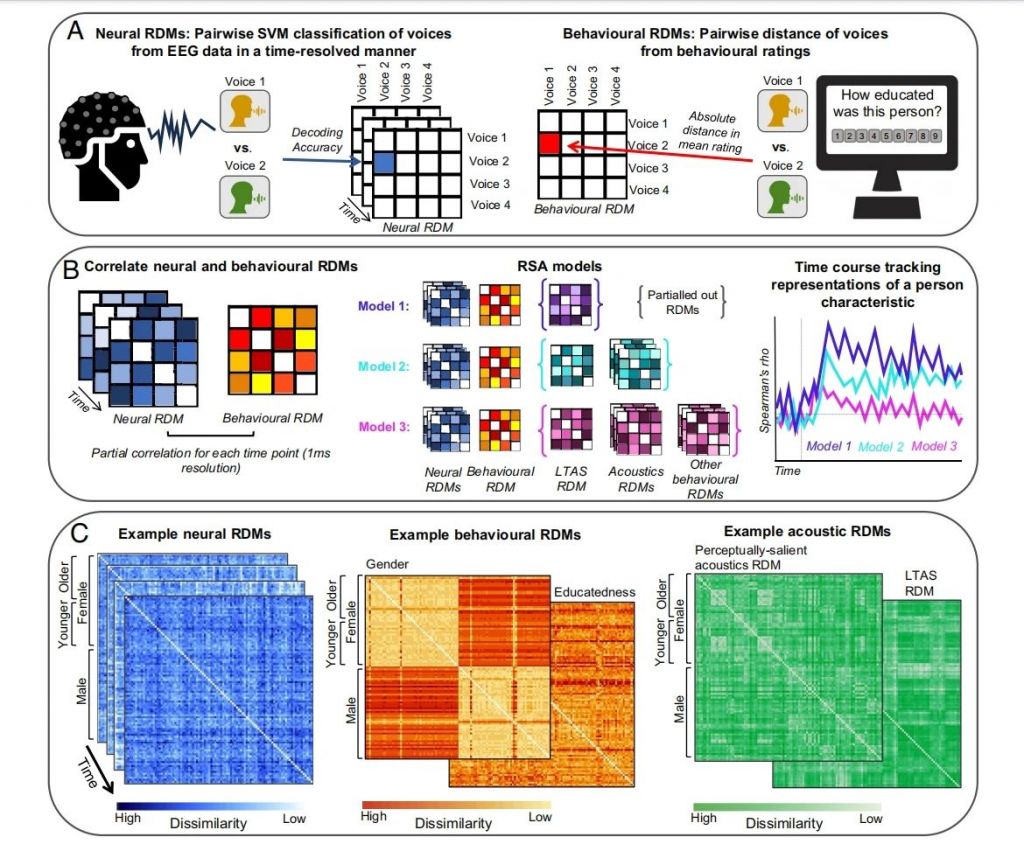
图2:RSA的分析方法。
(A)作为RSA的基础,我们创建了来自神经和行为数据的RDM。
(B)神经和行为RDM通过部分秩相关性关联,从神经数据中解码不同人物特征表征的时间轴。
(C)神经、行为和声学RDM示例
在66毫秒内,大脑就能分辨出不同的声音
对所有被试的神经RDM的上三角形(不包括对角线)每个时间点的所有成对解码准确度取平均值。结果显示,在刺激开始后66 ms至700 ms之间,大脑能够有效地区分不同的声音记录,并且在154毫秒时达到了最高的解码准确度峰值(平均准确度为53.1%,图3,灰线)。

图3:关于人物特征(性别、年龄、健康、主导性、吸引力、可信度、教育程度、和专业性)感知时间过程不同模型的比较;
最后一张图为每个声音可以从神经数据中解码出来的平均配对解码准确率
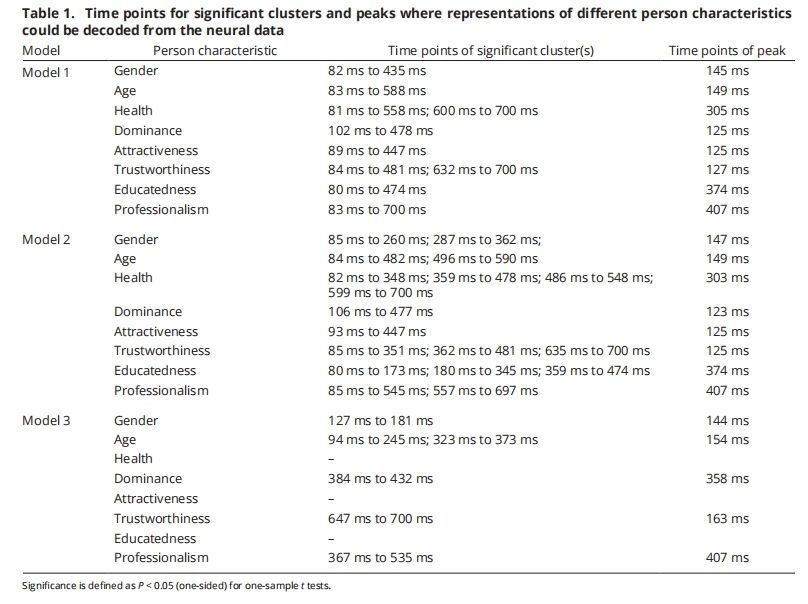
表1:不同的人的特征表征可以从神经数据中解码的显著簇和时间点
人物特征在大脑中表征的时间过程进程
通过计算和比较三种不同类型的RDM(神经、行为和声学)将EEG数据与行为评分数据进行关联。使用Spearman的部分秩相关性来评估神经RDM、行为RDM和声学RDM矩阵的下三角部分,揭示出每个时间点,神经反应、行为评分以及声学差异之间的相关性。具体来说,建立了三个模型(见图2B):
Model 1是基线模型,通过控制LTAS(长时平均频谱)的成对相似度矩阵,去除低级声学特性后,观察大脑对人物特征的表示方式。
Model 2在Model 1的基础上通过控制声学矩阵(LTAS矩阵和主成分矩阵),控制感知显著的声学特性(能被人类感知并影响人类对声音或人物特征感知的音频特征)差异。观察去除感知上显著的声学差异后,人物特征表示的变化。
Model 3控制了三个重要的变量:LTAS矩阵、感知显著的声学差异、所有已知的行为矩阵,计算了行为RDM和神经RDM之间的时间相关性,进而识别不受声音声学特性和其他感知特征影响的抽象人物特征。
Model 1:在听到声音的100毫秒内,可以解码身体、性格和社会特征的表征。
神经和行为RDM(代表性距离矩阵)之间显著相关性,所有人物特征的表征都可以在刺激开始后80 ms到102 ms之间被检测到,并在100 ms到200 ms之间达到第一个峰值,这些表征通常会持续到至少435 ms,如性别特征。在持续时间上,性别、主导性、吸引力、教育程度等特征的表示通常在刺激结束后不久便检测不到了,其他人物特征(如健康、信任度、专业性等)则可以持续更长时间,如专业性的表征在采样时间窗口的末尾仍然显著(见图3,紫色线,表1)。
Model 1证明人物特征的表征并非分阶段出现,而是所有特征的表征几乎同步出现。
Model 2:感知显著的声学特性与人物特征感知的早期阶段密切相关
Model 2的结果表明:感知显著的声学特性对人物特征的影响在时间上与Model 1类似,但性别感知的时间范围有所变化。在Model 2中,性别的表征只能在85毫秒到362毫秒之间被检测到(参见图4,蓝色线,表1)。
感知显著的声学特性主要影响的是人物特征感知的早期阶段(表2):相较于Model 1,在Model 2中,性别、健康、主导性和吸引力四个特征在96 ms到236 ms的时间窗口内,神经RDM和行为RDM之间的相关性显著降低。而可信度、教育程度、和专业性这些特征,感知显著声学特征对其表征的影响持续时间较长,延续至388 ms及之后。
排除了感知显著的声学特征后,人物特征的表征依然能够在80 ms到至少435 ms的时间范围内通过EEG数据显现出来,表明人物特征的表征不仅仅依赖于声学信息,而是由更高层次的认知处理形成的。
Model 3: 独立、抽象的人物特征表征在不同时间点出现
Model 3的目标是检测是否以及何时能够发现独立于声学特性和其他人物特征(如性别、年龄等)的抽象神经表征。通过双样本t检验发现,与Model 1相比,Model 3中神经RDM和行为RDM之间的相关性显著较低(见图3,粉色线和表2)。这表明,在Model 3中,大多数人物特征的独立神经表征消失了。通过单样本t检验发现,健康、吸引力和教育程度这三个特征的抽象表征在Model 3中完全消失。性别(127 ms到181 ms)和年龄(94 ms到373 ms)的抽象表征仍然可以在较早的时间段被检测到,而主导性(384 ms到432 ms)、可信度(647 ms到700 ms)和专业性(367 ms到535 ms)的独立抽象表征则出现在较晚的时间段。
这表明,在去除声学信息和其他人物特征后,只有部分抽象人物特征的表征仍然可以被检测到,尤其是性别和年龄,而其他如健康、吸引力等特征则完全消失。

表2:不同模型对比的时间过程差异
四、总结
人物特征的感知过程并非一蹴而就,而是分阶段、渐进式的过程。早期的声学信息对人物特征的表征有重要影响,随着时间推移,这些表征逐渐变得抽象并独立于声学特性。不同类型的人物特征在大脑中的表征出现时间也不同,身体特征较早,而个性和社会特征稍晚。人物特征的感知可能会出现过度概括(overgeneralization)和光环效应(halo effect),并导致人物特征之间的高相关性,但这一解释仍然是推测性的(speculative),需要更多的未来研究来验证这种因果关系的层次结构是否真实存在。
本研究结果与最新的理论模型相一致,并为我们理解通过声音感知他人时的大脑计算过程提供了新的视角。

 打电话
打电话

 微信
微信

 QQ
QQ

 产品中心
产品中心



