





8月10日晚20点,中国科学院心理研究所杜忆研究员作为脑客中国科研第67位讲者为大家带来主题为《多模态言语感知与理解的脑环路机制》的报告。以下为报告部分内容:

1言语感知和理解的特点
我们先介绍一些言语感知和理解的背景知识。

1.言语感知与理解极具挑战性:在日常生活中,我们都是在一些复杂的环境下进行言语感知,比如有背景噪音、背景音乐、甚至其他人同时在说话。比较著名的就是鸡尾酒会问题,如下图所示:

如果我们关心的是说话人B的语音,但是到达耳朵的其实是好多人声整合在一起的语音,如何提取出我们关心的目标语音信号其实是一件很难的事情。现在我们遇到过的一些语音识别软件在这方面能力做的不是很好,但人脑其实可以很简单做到这样一件事,是因为存在选择性的注意机制。
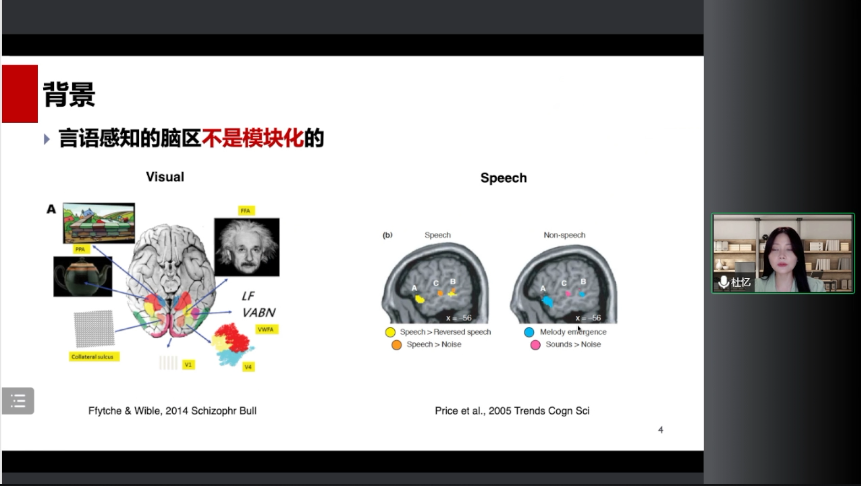
2.言语感知的脑区不是模块化的:我们知道大脑存在对于人脸加工的特异脑区,对位置加工的特异脑区,但并没有一个脑区在特意的加工语音。
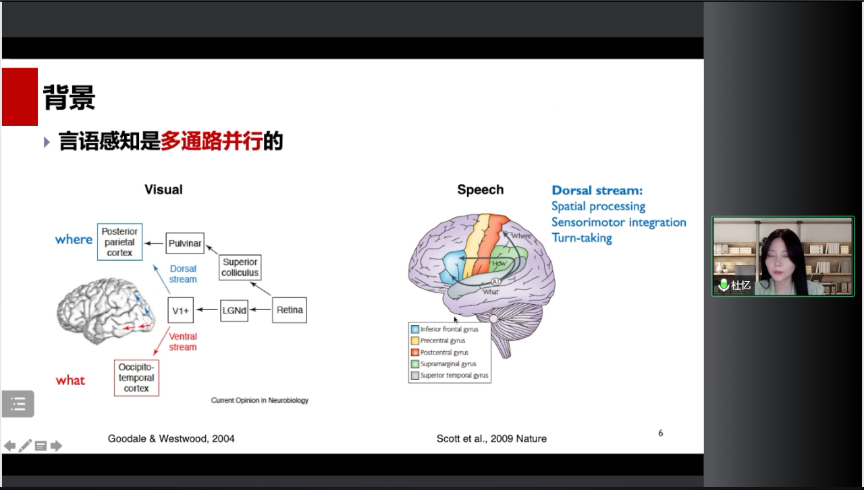
3.言语感知是多通道并行的:如同视觉通路一样,言语感知同样也是分成背侧通路和腹侧通路。
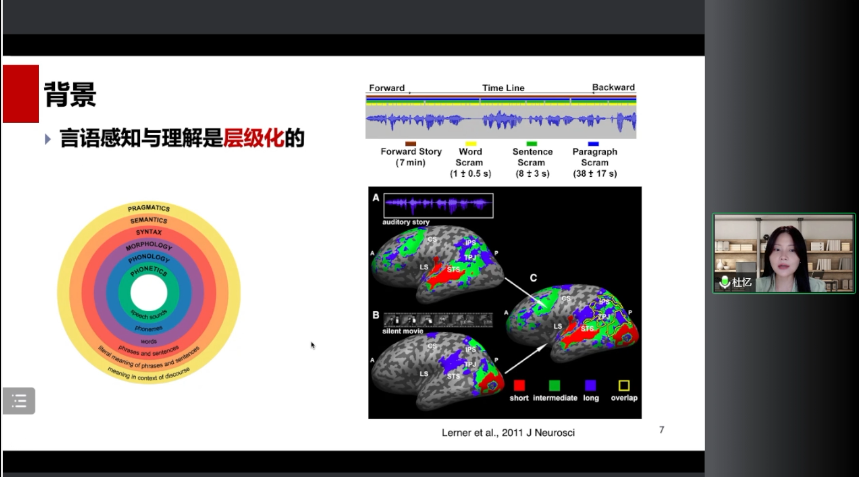
4.言语感知与理解是层级化的:语音有不同的时间尺度,不同的层级,从词到短语、句子,最后组成一个篇章。所以你可以看到大脑对于这样的一个不同时间尺度的语音信号的加工,它其实是存在着层次性的编码。
5.言语感知与理解是多模态的:比较著名的一个现象McGurk Effrct,视觉信息会严重地影响到你的听觉感知。语音信号放的是/ba/,唇动信息给出的是/ga/;如果你睁开眼看到这个视频,听语音的话,你的知觉应该是听到的是一个/da/,而闭上眼睛就会只听到/ba/。

6.言语感知与理解是预测式的:如言语感知和理解是将具有复杂动态结构的声学信号投射到词义表征的过程。听者可以利用先验知识和约束(包括语法、句法、转移概率、视觉运动线索等)来预测下一时刻的语音输入,该过程可被贝叶斯推理模拟。

2言语感知与理解和言语生成密切相关
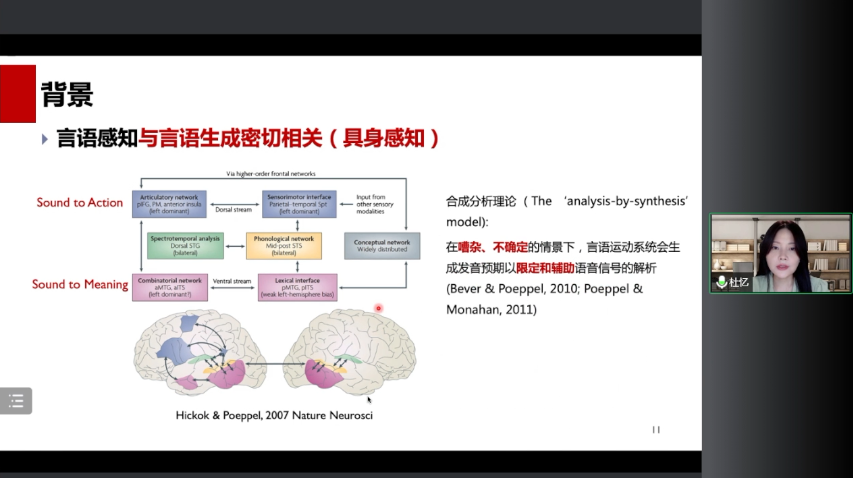
言语感知与理解和言语生成具有密切的关系。比如左边这个甲骨文文字,它的左部分是耳朵的意思,下面部分代表的是口,它表示的是我们现在的“听”字。这说明在我们听的过程中,其实存在听觉系统跟运动系统之间的一个整合。一个人说话时,他也能够听到自己的实时声音,这样的一个听觉反馈是有利于他更好地去控制他的发音动作。另外对于听者而言,当听到语音信号时,他不仅会利用到他的听觉系统,他自己跟发音相关的那些言语运动系统也会主动地模拟说话人的发音,来预测说话人的发音。
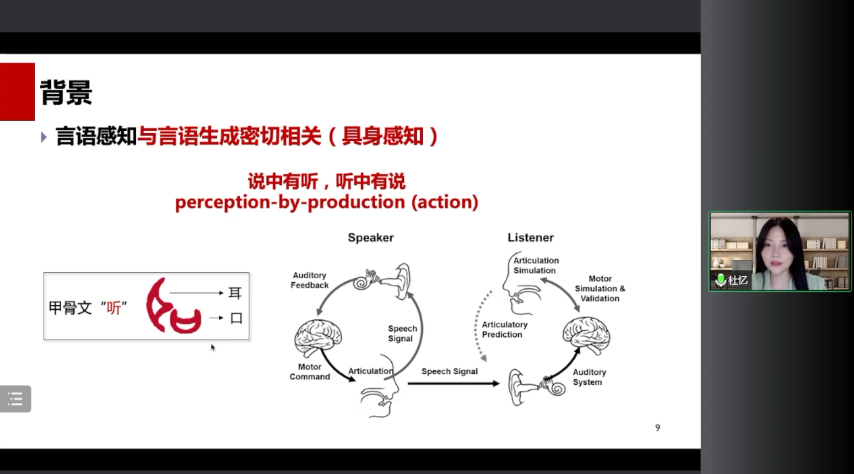
这样的过程其实是跟大脑内的镜像神经元系统密切相关的。大家知道镜像神经元系统最早是在猴脑上发现的,猕猴在执行一个动作或者是在观看他人执行一个动作的时候,会有一群神经元被激活,位于额叶的地方。这个脑区对应到我们人脑上,其实就是跟我们发音密切相关的布洛卡区和腹侧前运动皮层。近代有很多的脑成像研究也已经发现,我们的言语生成和言语感知功能区具有很多重叠的脑区,包括这些蓝色重叠的脑区其实都是镜像神经元所在的地方。

因此提出了一个语音加工的双流通路模型,合成分析理论认为:在嘈杂、不稳定的情境下,言语运动系统会生成发音预期以限定和辅助语音信号的解析。
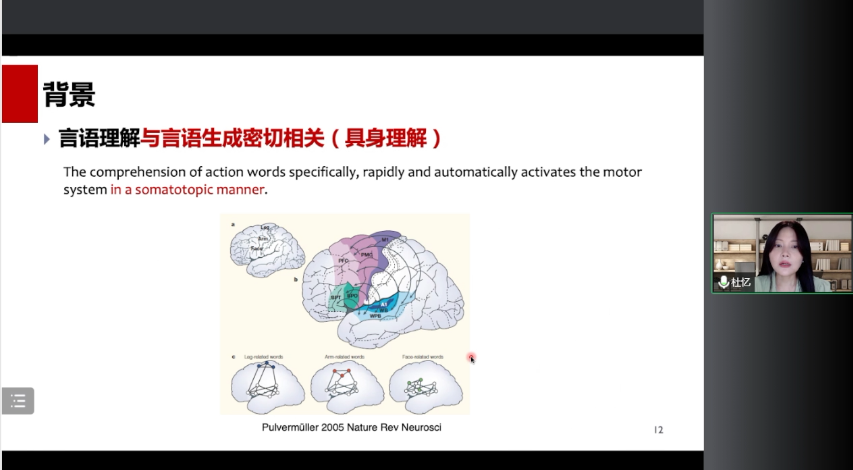
另外会有人发现,当我们在听到一些动作词的时候,我们会特意地去激活跟控制这些动作所属的身体部位相关的运动区。比如说你听到一些跟腿相关的运动区词汇时,你会激活控制腿部相关的运动区;如果你听到是跟面部发音相关的词汇时,你会激活更加腹侧的运动区域。
3三个相关研究
基于以上背景,和大家介绍一下我们实验室所做的三个研究。
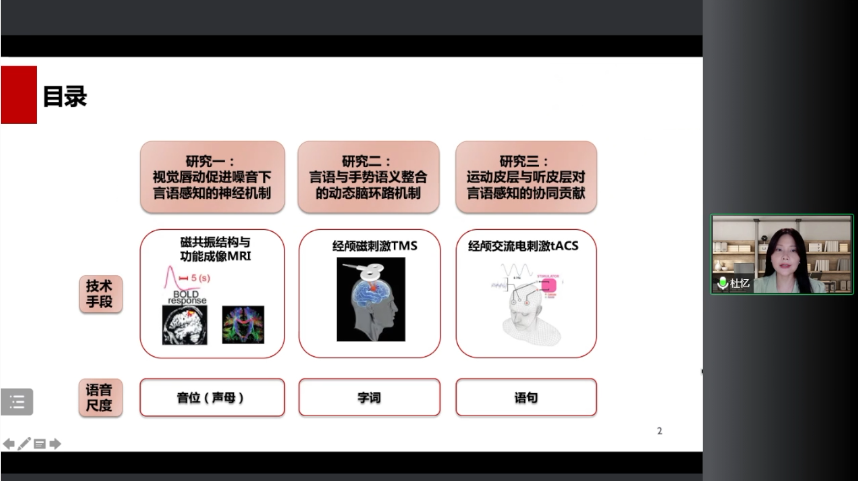
第一个研究是关心视觉唇动促进噪音下言语感知的神经机制,用到的技术手段包括磁共振的结构和功能成像。它的语音尺度是在音位,一个声母的层级,很短的一个时间单元。
研究二是关心言语和手势语义整合的动态脑环路机制。我们用到的技术手段是经颅磁刺激TMS,它的语音尺度是在字词。
第三个研究关心的是运动皮层和听皮层对言语感知的协同贡献。用到的技术手段是一个经交流电刺激TACS,它的语音层级是在一个语句的层级上进行的。
可以看到三个研究分别用了不同的技术,关心的语音尺度也是不一样的,一个比一个更长。
观看本期及往期精彩视频内容请扫描下方二维码观看。

扫描二维码
观看完整视频
END
